Large-scale video diffusion models often fail to preserve 3D structure over time,
causing geometric drift and implausible motion under viewpoint changes. VideoWeave
is a latent-space post-training framework that uses implicit geometry-model features
to constrain the generative distribution without relying on explicit reconstructed
depth maps, point clouds, or 3D structures. It adapts geometry features into latents,
jointly models them with video latents in a shared denoising space, and distills the
resulting joint score field into an efficient generator. Together with GeoVid-80K,
VideoWeave improves geometric coherence while preserving strong visual quality for
text-to-video and image-to-video generation.
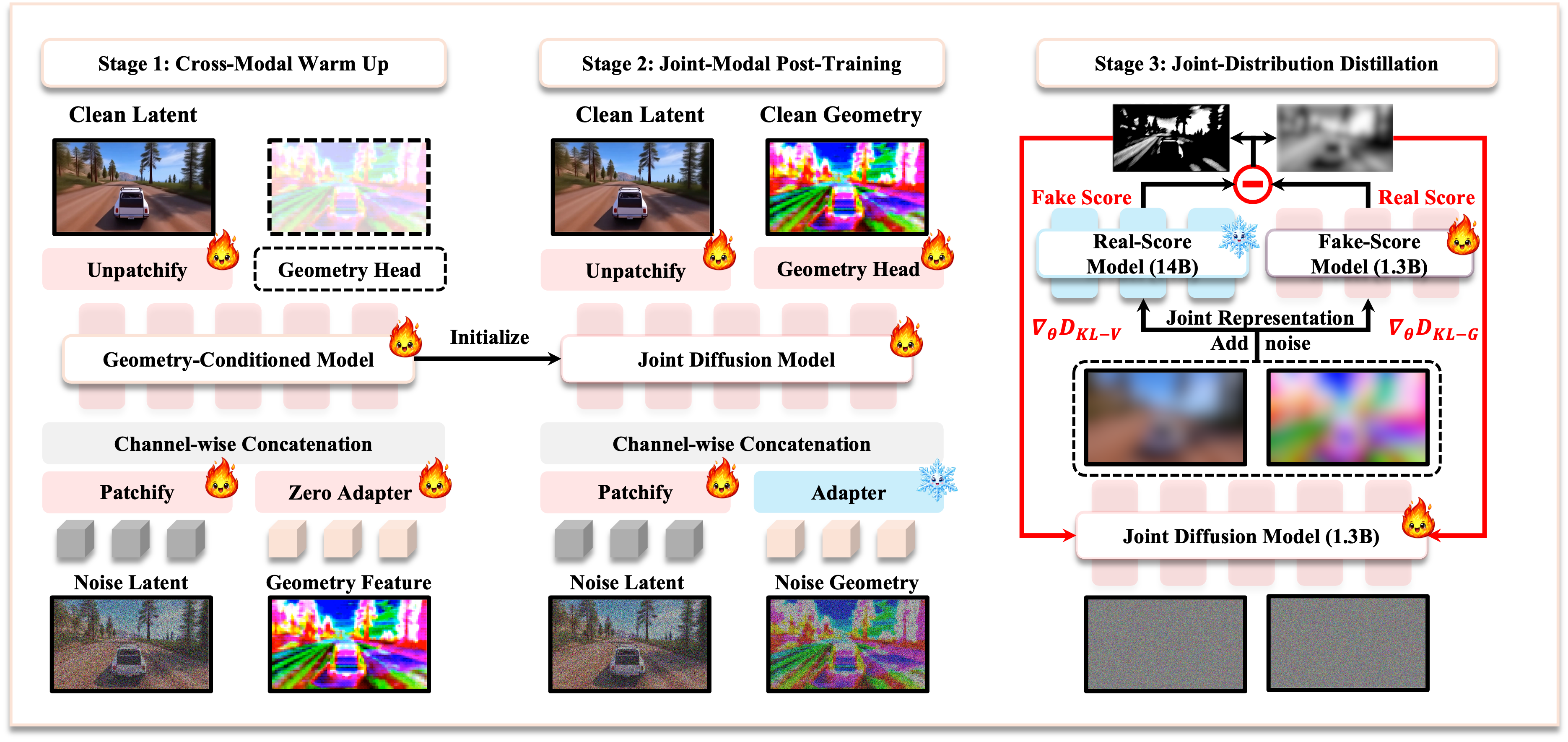
Overview
We present VideoWeave, a latent-space post-training framework
that changes the role of geometry from an explicit reconstruction-derived
guidance signal into a temporary latent companion of the video during training.
The framework progressively adapts implicit geometry features, learns a unified
geometry-video denoising space, and distills the joint score field into a compact
student generator. At inference time, the geometry latent is discarded, enabling
efficient video generation with a distilled 3D-aware prior.
Results
VideoWeave is evaluated in both text-to-video and image-to-video settings. Across
video quality, 3D reconstruction consistency, and epipolar consistency metrics, it
improves spatial coherence and long-range geometric stability while maintaining
competitive visual fidelity.
T2V
Text-to-video Results
Text-conditioned generations preserve scene structure across extended camera
motion while keeping object appearance and layout coherent over time.
Sample 01T2VSample 02T2VSample 03T2VSample 04T2V
I2V
Image-to-video Results
Image-conditioned generations extend the input view with stable geometry,
consistent camera trajectories, and reduced drift across long horizons.
Sample 01I2VSample 02I2VSample 03I2VSample 04I2V
Joint
Joint Generation Results
VideoWeave jointly denoises video latents and compressed
geometry-feature latents, producing both the final video and its geometry-feature
companion. The geometry features participate only during joint denoising and are
discarded after denoising is complete.